
Overview
The Letraz database is the backbone of our application’s data management, supporting both our core business logic and ancillary services. Designed with scalability, flexibility, and clarity in mind, the schema has been refined over time, and we’ll continue to do so as the schema evolves with our project. Below is a visual representation of the database schema: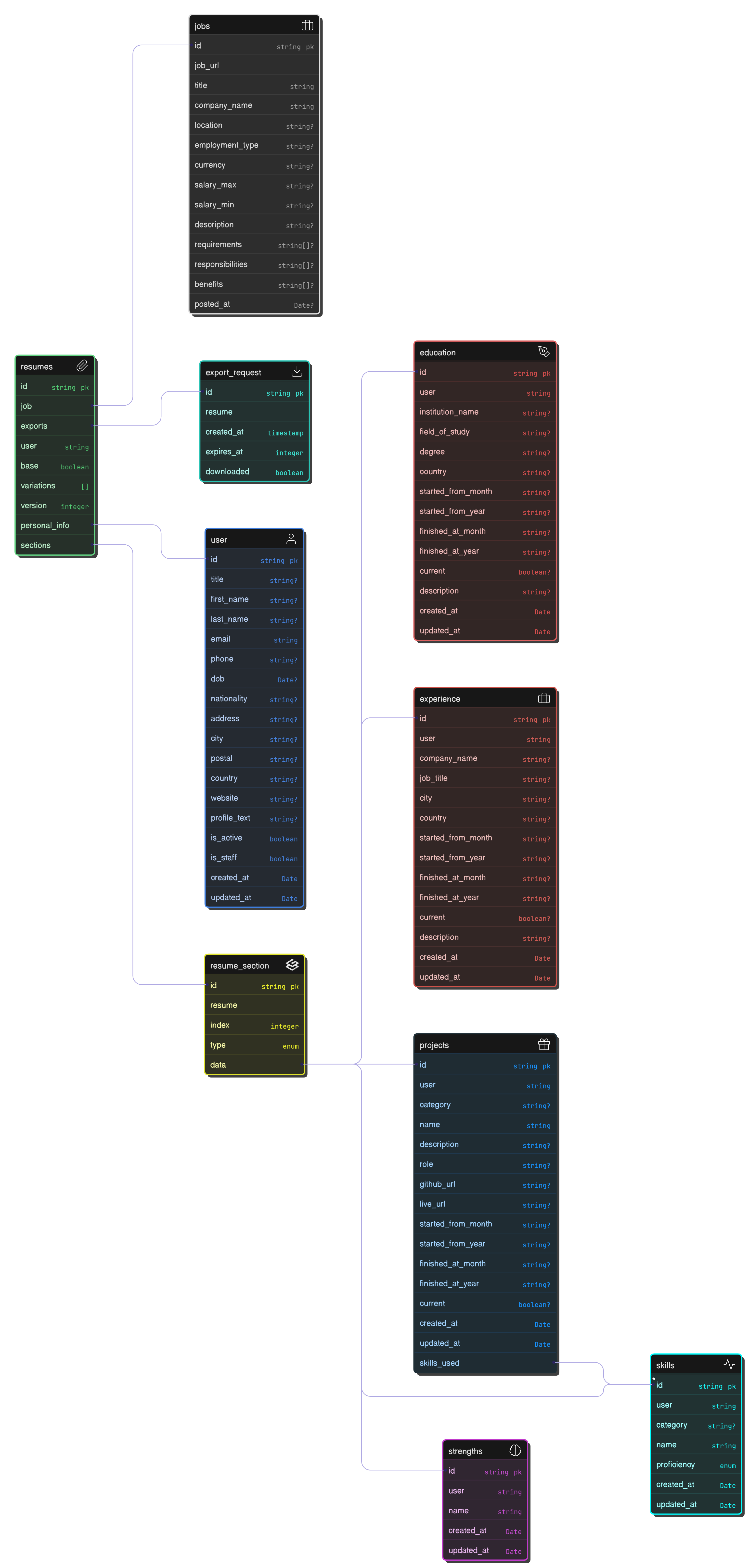
Design Philosophy
The Letraz database follows a structured approach with a focus on modularity and scalability. The key principles guiding our schema design are:- User-Centric Data Organization: Each user owns and manages their resumes, experiences, education, projects, skills, and strengths.
- Modular Resume Composition: Resumes are constructed from distinct sections, allowing flexibility and customization.
- Job Matching and Optimization: The system stores job postings, allowing intelligent resume tailoring.
- Efficient Export and Versioning: Export requests and version control ensure that users can manage multiple variations of their resumes seamlessly.
Schema Overview
Below is a breakdown of the main entities in the database:1. User Table (user)
- Stores personal information such as name, email, contact details, nationality, and profile text.
- Tracks account status with fields like
is_activeandis_staff. - Users are linked to their resumes and other related entities.
2. Resumes Table (resumes)
- Represents individual resumes created by users.
- Contains metadata such as
base(indicating if it’s a primary resume) andpersonal_info. - Connected to multiple
resume_sectionrecords, allowing flexible customization. - Now includes a reference to
job, indicating if a resume is linked to a specific job posting.
3. Resume Sections Table (resume_section)
- Stores individual components of a resume (e.g., experience, education, skills).
- Each section is linked to a
resumeand has anindexfield to maintain order. - The
typefield is an enum representing different section types.
4. Education Table (education)
- Captures academic qualifications of users.
- Fields include
institution_name,degree,field_of_study, andduration. - Supports ongoing education with the
currentboolean flag.
5. Experience Table (experience)
- Logs professional experiences.
- Fields include
company_name,job_title,location,duration, anddescription.
6. Projects Table (projects)
- Tracks individual projects completed by users.
- Includes
category,name,description,role, andduration. - Project specific fields:
github_url,live_url, andskills_usedfor better portfolio integration.
7. Skills Table (skills)
- Stores skills associated with users.
- Includes
name,category, andproficiencyas an enum.
8. Strengths Table (strengths)
- Captures user strengths that aren’t necessarily hard skills.
9. Jobs Table (jobs)
- Stores job postings.
- Fields include
title,company_name,location,employment_type,salary_range,description, andrequirements. - Used for AI-powered resume tailoring.
10. Export Requests Table (export_request)
- Tracks requests for exporting resumes.
- Contains metadata such as
created_at,expires_at, anddownloaded. - Now references
job, allowing better tracking of exported resumes tied to specific job applications.
Future Considerations
- Performance Optimization: Indexing frequently queried fields.
- Data Privacy: Ensuring user data security and compliance.
- Enhanced Resume Customization: Additional section types and templates.